Disaster recovery (DR) involves a set of policies, tools and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a disaster. DR focuses on the IT or technology systems supporting critical business functions, as opposed to business continuity, which involves keeping all essential aspects of a business functioning despite significant disruptive events. DR, as part of IT Service Continuity (ITSC) can therefore be considered as a subset of Business Continuity Planning (BCP).
DR planning begins with a business impact analysis that defines two key metrics:
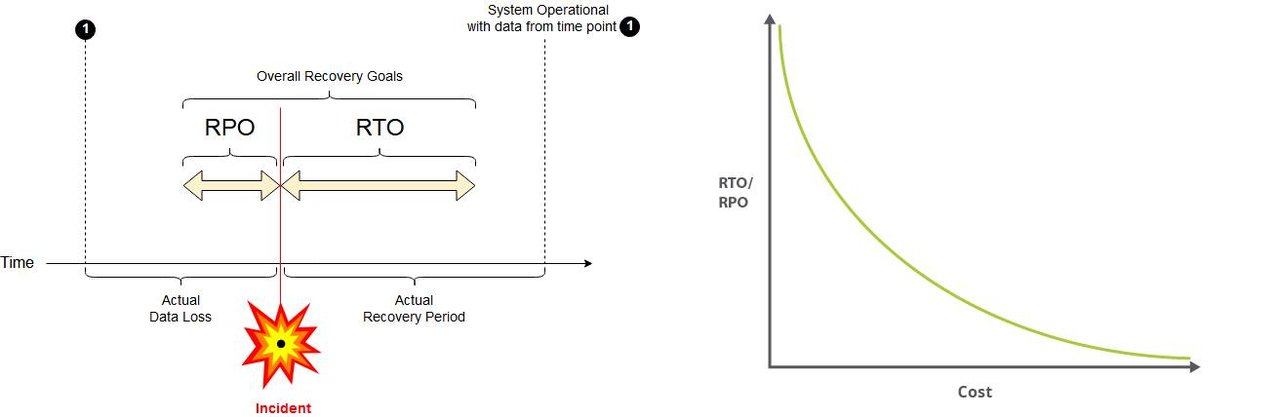
- Recovery Point Objective (RPO) - recent transactions
- Recovery Time Objective (RTO) - time intervals
Recovery Point Objective (RPO)
RPO, which is the maximum acceptable length of time during which data might be lost from your application due to a major incident. In short, RPO is the maximum age of files that an organization must recover from backup storage for normal operations to resume after a disaster. The RPO determines the minimum frequency of backups. For example, if an organization has an RPO of four hours, the system must back up at least every four hours.
As a brief example, transactions data that must be paid in two hours are have shorter RPO than unpaid transactions which due date in 24 hours. If the backup from four hours ago is restored, we may able to recover transactions which due in 24 hours, but lost some transactions that entried and paid within two hours during backup and incident occurred.
The RPO metric varies based on the ways that the data is used. For example, user data that's frequently modified could have an RPO of just a few minutes. In contrast, less critical, infrequently modified data could have an RPO of several hours. If RPO is measured in minutes (or even a few hours), then in practice, off-site mirrored backups must be continuously maintained – a daily off-site backup on tape will not suffice.
Recovery Time Objective (RTO)
RTO, which is the maximum acceptable length of time to recover files from backup storage and resume normal operations. In other words, the recovery time objective is the maximum amount of downtime an organization can handle. This value is usually defined as part of a larger service level agreement (SLA). As an example, point of sale (POS) systems will have longer RTO than core (backend) systems, since during the downtime, sales can be accepted using direct sale, via phone, or email.
Source: Wikimedia & Google Cloud
CPO & CTO
RTO and the RPO must be balanced, along with all the other major system design criteria. Typically, the smaller your RTO and RPO values are (that is, the faster your application must recover from an interruption), the more your application will cost to run. Because smaller RTO and RPO values often mean greater complexity.
Types of Disaster Recovery Plans
DR sites can be internal or external. Companies with large information requirements and aggressive RTOs are more likely to use an internal DR site, which is typically a second data center. The internal site option is often much more expensive than an external site, but a major advantage is control over all aspects of the disaster recovery process. An organization also can outsource their DR to external provider. If external provider owns and operates the DR site, that's means the organization using external DR site. Nowadays, instead of physical installation, a cloud recovery site is gaining momentum as another option. This method is cheaper and uses less company resources and infrastructure, but the organization need to be mindful of security and bandwidth.
When it comes to implementing your BCP, there are different strategy that you can adopt for the DR element. These strategy (or we call it DR patterns) are considered to be cold, warm, or hot. These patterns indicate how readily the system can recover when something goes wrong. An analogy might be what you would do if you were driving and punctured a car tire:
Cold DR
Cold DR means that the organization most likely already provisioned infrastructure to support IT systems and data, but not the technology until the organization activates DR plans. In a lot of cases Cold DR site essentially nothing more than data center space, power and connectivity that are ready and available whenever needed in the event of a disaster.
Analogy: You have no spare tire, so you must call someone to come to you with a new tire and replace it. Your trip stops until help arrives to make the repair.
Benefits: Lowest cost
Disadvantages: Availability; longest recovery timescales; limited testing available; only available for a limited period following a disaster; additional recovery services needed.
There are a lot perception that Cold DR means start from zero, and if the effort is essentially same with bringing up main site, why we need Cold DR? No, it's not, Cold DR doesn't means start from zero, In my experiences,
Warm DR
Warm DR means that the infrastructure and technology are ready when the organization activates DR plans, but not the data. Warm DR allows organization to pre-install and configure bandwidth needs. In the event of a disaster, what organization need to do is load their software and data at the new site to get back in business. As example; when DR activated, IT just need to restore from backup database, and deploy application to the server. IT need to bring up all servers, following by steps of swing process for DR to take over.
Analogy: You have a spare tire and a replacement kit, so you can get back on the road using what you have in your car. However, you must stop your journey to repair the problem.
Benefits: Lower cost; reasonable availability.
Disadvantages:Availability; recovery timescales are longer; limited testing available; only available for a limited period following a disaster.
Hot DR
Hot DR means that the infrastructure, technology, even data are ready when the organization activates DR plans. As example; every deployment, the same packages deployed to main site also deployed to DR site. Database also mirrored to DR database. Servers up, and DR network (IP address) all sets. In the event of a disaster, the swing process will ensure the DR will take over main site.
Analogy: You have run-flat tires. You might need to slow down a little, but there is no immediate impact on your journey. Your tires run well enough that you can continue (although you must eventually address the issue).
Benefits: Available immediately; dedicated.
Disadvantages: Cost; Complexity, management.
Distance is a key element of a disaster recovery site. A closer site is easier to manage, but it should be far enough away that it's not impacted by a major disaster affecting the primary data center. Sites farther away may require more staff and drive up costs.
Component DR and Full DR
There are many IT systems supporting an organization. Let say in Bank ABC, System A is an online trading system for forex where public customers can trade. System B is an internal system for forex. And System C is back-end core system, were many core banking functionality and settlement - not just forex - is processed. Batch jobs interfaces is done via System A to System B, and System B to System C. Component DR refer to individual systems. If disaster happen on System A, only System A switch to DR mode, but System B and System C still in main production mode. Full DR happen to all systems, as example when a main data center hosting these systems "down", the whole systems swith to DR mode in DR Data Center.
Articles are based on writer experience working in financial industry, from technical perspective.
Source:
- Wikipedia: Disaster recovery and Backup site.
- Disaster Recovery Planning Guide

Desson AriawanProgrammer
